
About Me
I am a doctoral researcher with a PhD in Artificial Intelligence (pending final corrections). My research brought together expertise in Explainable AI, Reinforcement Learning, and User Interface design to develop SYMPLEX (Symbolically-constrained Policy Learning through Exploration and Expert Interaction) - a novel system that enables reinforcement learning agents to learn and operate under explicit logical constraints. This work has formed the basis of several publications in leading AI conferences and journals.
Beyond my PhD, I have undertaken research placements at IBM, where I contributed to the design of user-centred interactive machine learning interfaces, and at the Alan Turing Institute, where I collaborated with the Ministry of Justice to develop an information retrieval system that empowers victims to better understand their rights under relevant legislation.
PhD Thesis Summary
My thesis presented a neurosymbolic framework called Symplex (Symbolically-constrained Policy Learning from Exploration/Examples) which combines policy optimisation with example-based user interaction designed to elucidate additional preferences that end users find easier to illustrate than directly formalise. To achieve this, Symplex interleaves a symbolic system based on interactive Inductive Logic Programming (ILP) which learns user preferences as first-order logic constraints derived from example demonstrations, with a neural system based on Deep Q learning (DQL) that learns near-optimal policies subject to those constraints. The core contribution of Symplex lies in its ability to satisfy three key properties:
- learned constraints take the form of first-order symbolic clauses making them inherently human-interpretable and generalisable across different environment configurations;
- users are only required to provide examples of desirable behaviour, rather than formal specifications, and can harness interactive feedback mechanisms to refine constraints, resolve conflicts and provide counter-examples;
- constraints are encoded as low-level state-action penalties in the DQL reward function so can be overridden to account for newly-provided user demonstrations;
Ultimately, this work reinforces the value of combining autonomous learning with both interpretable symbolic machine learning, and knowledge-driven user interaction, in order to support trustworthy, user-aligned agentic systems.
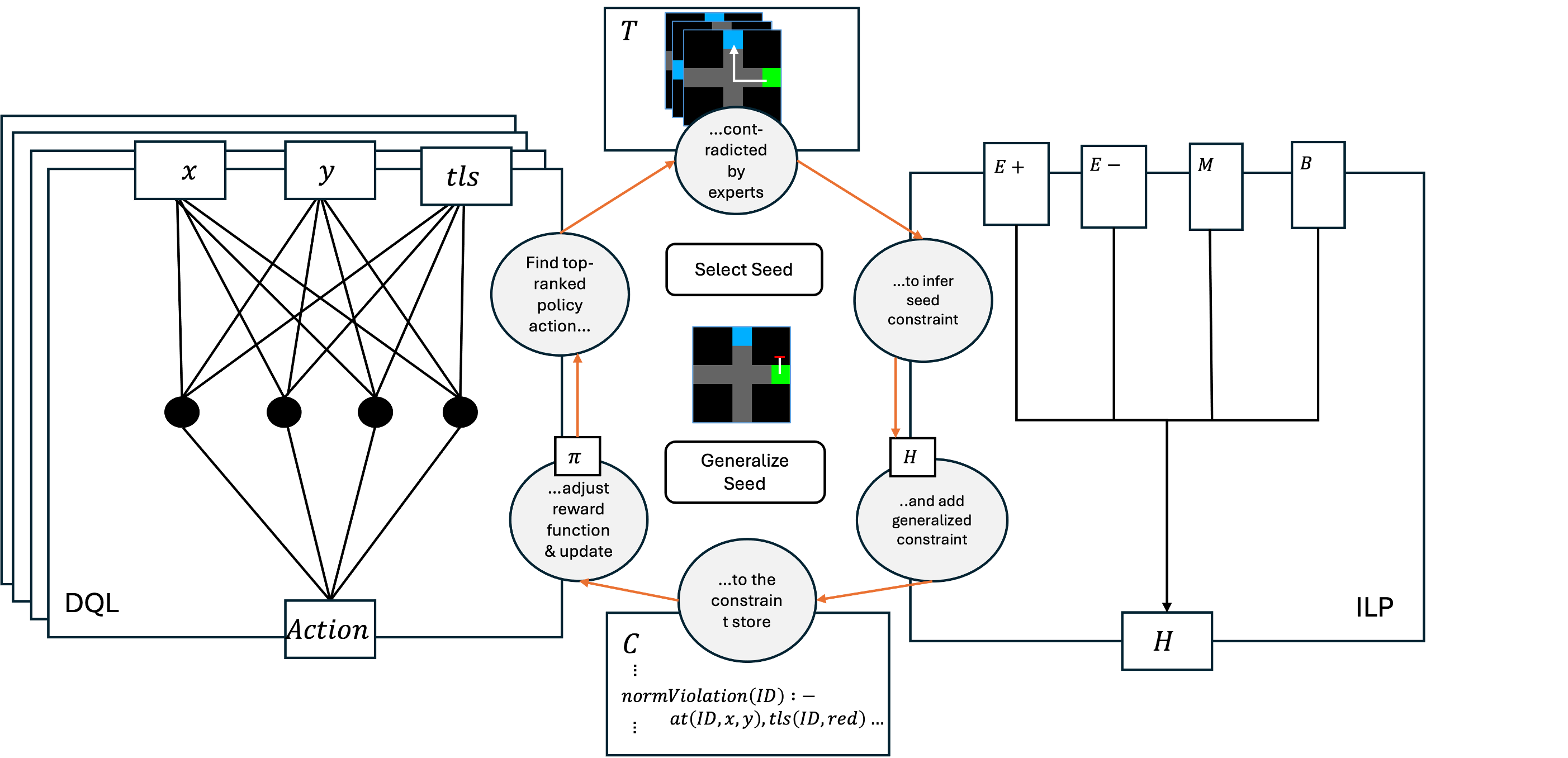 The above image demonstrates how the SYMPLEX system interleaves exploration-based learning with symbolic machine learning to elucidate a set of explicit constraints under which a Reinforcement Learning agent must operate.
The above image demonstrates how the SYMPLEX system interleaves exploration-based learning with symbolic machine learning to elucidate a set of explicit constraints under which a Reinforcement Learning agent must operate.